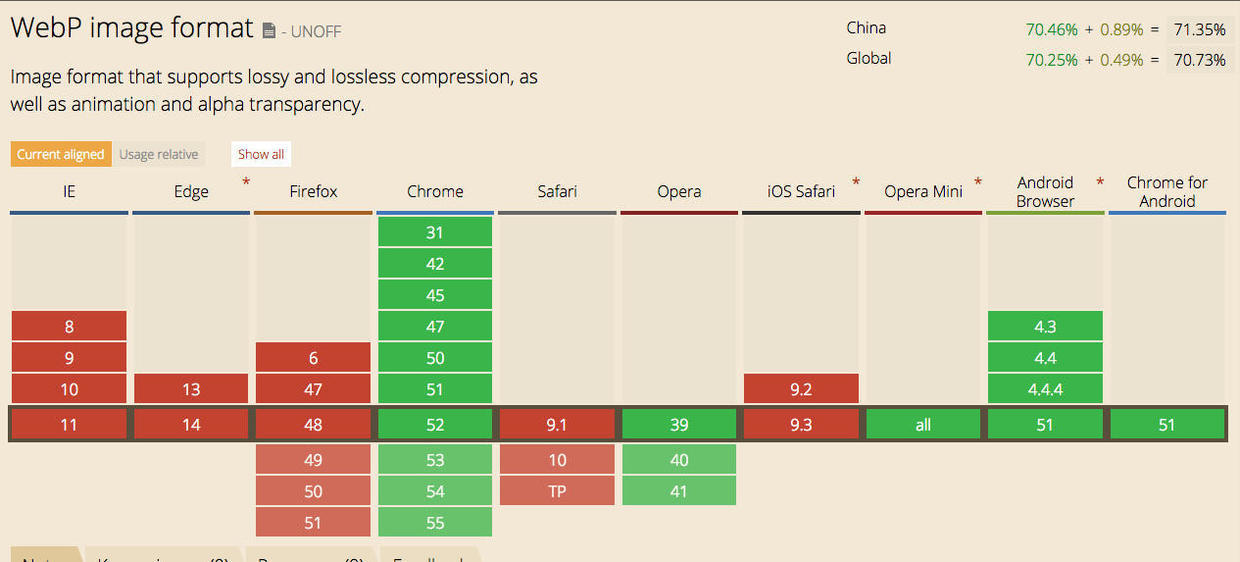
Android added webp support in version 4.0 and improved it in 4.2.1:
4.0+ (Ice Cream Sandwich): basic webp support
4.2.1+ (Jelly Beam MR1): support for transparency and losless wepb
Fresco handles webp images by default if the OS supports it. So you can use webp with 4.0+ and trasparency and losless webps from 4.2.1.
Fresco also supports webp for older OS versions. The only thing you need to do is add thewebpsupportlibrary to your dependencies. So if you want to use webps on Gingerbread just add the following line to your gradle build file:
compile ‘com.facebook.fresco:webpsupport:1.3.0’
/** Performs the decode synchronously. */privatevoiddoDecode(EncodedImageencodedImage,@Statusintstatus){if(isFinished()||!EncodedImage.isValid(encodedImage)){return;}finalStringimageFormatStr;ImageFormatimageFormat=encodedImage.getImageFormat();if(imageFormat!=null){imageFormatStr=imageFormat.getName();}else{imageFormatStr="unknown";}finalStringencodedImageSize;finalStringsampleSize;finalbooleanisLast=isLast(status);finalbooleanisLastAndComplete=isLast&&!statusHasFlag(status,IS_PARTIAL_RESULT);finalbooleanisPlaceholder=statusHasFlag(status,IS_PLACEHOLDER);if(encodedImage!=null){encodedImageSize=encodedImage.getWidth()+"x"+encodedImage.getHeight();sampleSize=String.valueOf(encodedImage.getSampleSize());}else{// We should never be hereencodedImageSize="unknown";sampleSize="unknown";}finalStringrequestedSizeStr;finalResizeOptionsresizeOptions=mProducerContext.getImageRequest().getResizeOptions();if(resizeOptions!=null){requestedSizeStr=resizeOptions.width+"x"+resizeOptions.height;}else{requestedSizeStr="unknown";}try{longqueueTime=mJobScheduler.getQueuedTime();longdecodeDuration=-1;StringimageUrl=encodedImage.getEncodedCacheKey().getUriString();intlength=isLastAndComplete||isPlaceholder?encodedImage.getSize():getIntermediateImageEndOffset(encodedImage);QualityInfoquality=isLastAndComplete||isPlaceholder?ImmutableQualityInfo.FULL_QUALITY:getQualityInfo();mProducerListener.onProducerStart(mProducerContext.getId(),PRODUCER_NAME);CloseableImageimage=null;try{longnowTime=System.currentTimeMillis();image=mImageDecoder.decode(encodedImage,length,quality,mImageDecodeOptions);decodeDuration=System.currentTimeMillis()-nowTime;}catch(Exceptione){Map<String,String>extraMap=getExtraMap(image,imageUrl,queueTime,decodeDuration,quality,isLast,imageFormatStr,encodedImageSize,requestedSizeStr,sampleSize);mProducerListener.onProducerFinishWithFailure(mProducerContext.getId(),PRODUCER_NAME,e,extraMap);handleError(e);return;}Map<String,String>extraMap=getExtraMap(image,imageUrl,queueTime,decodeDuration,quality,isLast,imageFormatStr,encodedImageSize,requestedSizeStr,sampleSize);mProducerListener.onProducerFinishWithSuccess(mProducerContext.getId(),PRODUCER_NAME,extraMap);handleResult(image,status);}finally{EncodedImage.closeSafely(encodedImage);}}
publicinterfacePlatformDecoder{/** * Creates a bitmap from encoded bytes. Supports JPEG but callers should use {@link * #decodeJPEGFromEncodedImage} for partial JPEGs. * * @param encodedImage the reference to the encoded image with the reference to the encoded bytes * @param bitmapConfig the {@link android.graphics.Bitmap.Config} used to create the decoded * Bitmap * @return the bitmap * @throws TooManyBitmapsException if the pool is full * @throws java.lang.OutOfMemoryError if the Bitmap cannot be allocated */CloseableReference<Bitmap>decodeFromEncodedImage(finalEncodedImageencodedImage,Bitmap.ConfigbitmapConfig);/** * Creates a bitmap from encoded JPEG bytes. Supports a partial JPEG image. * * @param encodedImage the reference to the encoded image with the reference to the encoded bytes * @param bitmapConfig the {@link android.graphics.Bitmap.Config} used to create the decoded * Bitmap * @param length the number of encoded bytes in the buffer * @return the bitmap * @throws TooManyBitmapsException if the pool is full * @throws java.lang.OutOfMemoryError if the Bitmap cannot be allocated */CloseableReference<Bitmap>decodeJPEGFromEncodedImage(EncodedImageencodedImage,Bitmap.ConfigbitmapConfig,intlength);}getBitmapFactoryOptions获取BitmapFactory.OptionsdecodeByteArrayAsPurgeable获取bitmappinBitmap真正的decode
/*
* Called when a producer successfully finishes processing current unit of work.
* @param extraMap Additional parameters about the producer. This map is immutable and will
* throw an exception if attempts are made to modify it.
/
void onProducerFinishWithSuccess(String requestId, String producerName, @Nullable Map<String, >String> extraMap);
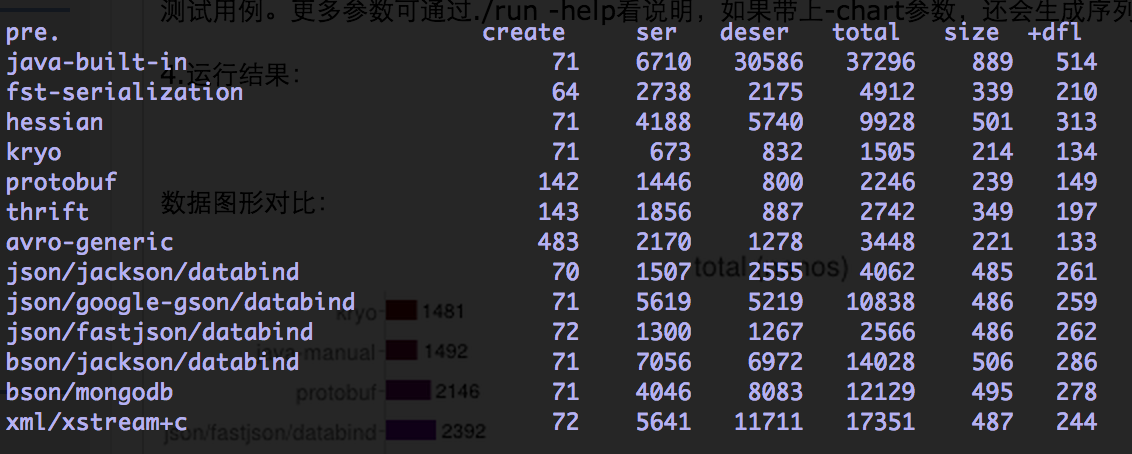
Fast Serialization reimplements Java Serialization with focus on speed, size and compatibility. This allows the use of FST with minimal code change.
FSTStructs implements a struct emulation to avoid de-/encoding completely. Use case is high performance message oriented software. Other applications are data exchange with other languages, reduction of FullGC by ‘flattening’ complex Objects, fast offheap, Control of data locality (CPU cache friendly) for high performance computational tasks, allocation free java programs.
rake new_post['new post on new computer']
git add .
git commit -m 'create a new post in new compter'
git push origin source #push source内容到repo上
rake deploy 发布blog
切到另一台B电脑上:
1234
cd octopress
git pull origin source # 同步source分支
cd octopress/_deploy
git pull origin master # 同步master分支, 因为之前rake dedploy会修改master的内容
前段时间云音乐Android小组打算自己搭建一个blog,用于总结跟记录工作中遇到的技术问题。之前自己在其他地方记录过几篇blog,也一直想搭个blog的玩玩,借此机会正好操练。
出于对Github极大的好感,自然就想到利用Github Page服务搭建一个blog,网络上已经存在大量关于利用Github与Octopress搭建blog的文章,但是质量参次不齐,实际我在搭建的过程中就遇到了不少问题,这里记录一下其他文章中忽略的一些细节,梳理一下流程,同时帮碰到相同问题的同学节省时间。可能少有人会跟我一样折腾,还打算在一台mac上维护两个octopress blog、其中一个octopress blog 还需要在多台设备上一起更新(android 小组),因此这篇blog先介绍创建一个常规octopress blog的步骤,之后再介绍下一台电脑上维护两个octopress blog 以及 一个octopress blog 在多个地方(电脑)上更新的方法。
配置github信息
默认你已经创建了github帐号,如果还没有,先到github上注册一个,记得起一个酷炫或者有特殊意义的username,这会是个稍候blog域名的prefix。并且默认你已经完成本机上完成github帐号信息的配置,如果还没有,请查看github help
url: # For rewriting urls for RSS, etc
title: # Used in the header and title tags
subtitle: # A description used in the header
author: # Your name, for RSS, Copyright, Metadata
simple_search: # Search engine for simple site search
description: # A default meta description for your site
date_format: # Format dates using Ruby's date strftime syntax
subscribe_rss: # Url for your blog's feed, defauts to /atom.xml
subscribe_email: # Url to subscribe by email (service required)
category_feeds: # Enable per category RSS feeds (defaults to false in 2.1)
email: # Email address for the RSS feed if you want it.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}